Simulation
Robust Action Diffusion via Contractive Score-based Sampling with Differential Equations
Diffusion policies have emerged as powerful generative models for offline policy
learning, where their sampling process can be rigorously characterized by a score
function guiding a stochastic differential equation (SDE). However, the same
score-based SDE modeling that grants diffusion policies the flexibility to learn diverse behavior also incurs discretization errors, large data requirements, and
inconsistencies in action generation. While not critical in image generation, these inaccuracies compound and lead to failure in continuous control settings.
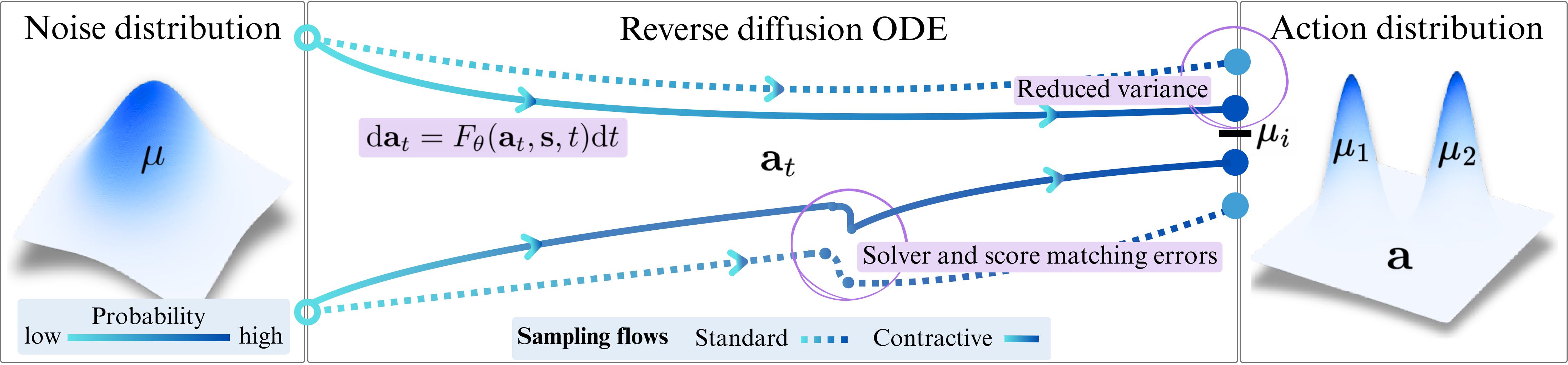
We introduce Contractive Diffusion Policies (CDPs) to induce contractive behavior in the sampling flows of diffusion SDEs. Contraction pulls nearby flows closer
to enhance robustness against solver and score errors while mitigating unwanted
action variance. We develop an in-depth theoretical analysis along with a practical implementation recipe to incorporate CDPs into existing diffusion policy architectures with minimal modification and negligible computational cost. Empirically, we evaluate CDPs for offline learning by conducting extensive experiments in
simulation and real-world.
While much of today's robotics research is driven by ever larger models and empirical scaling laws, we show substantial and theoretically grounded improvements to the action diffusion process itself by encouraging contractive flows in diffusion sampling. Across various benchmarks, contractive policies yield:
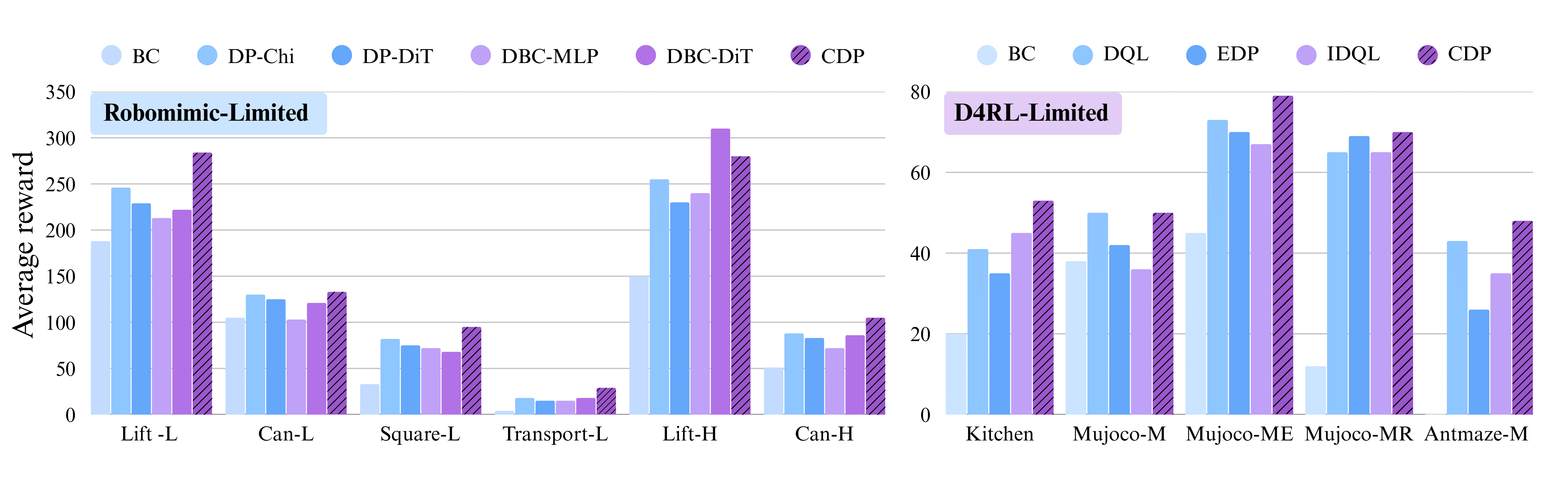
➤ higher average reward and success rates in offline learning settings, and
➤ minimal computational overhead with efficient eigenvalue computation.
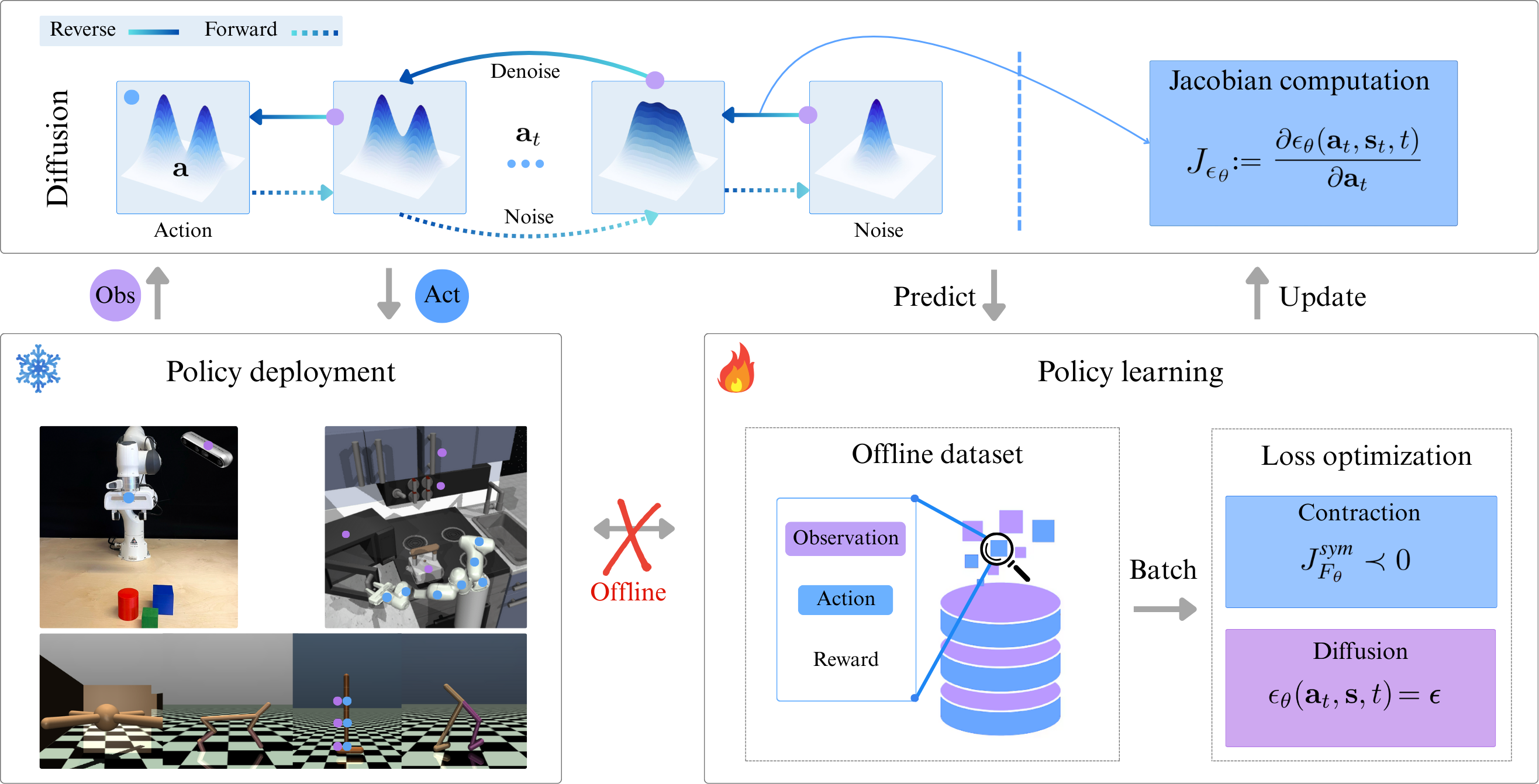
CDPs enhance robustness by pulling noisy action trajectories closer together through a contraction loss, which mitigates solver and score errors while stabilizing learning.
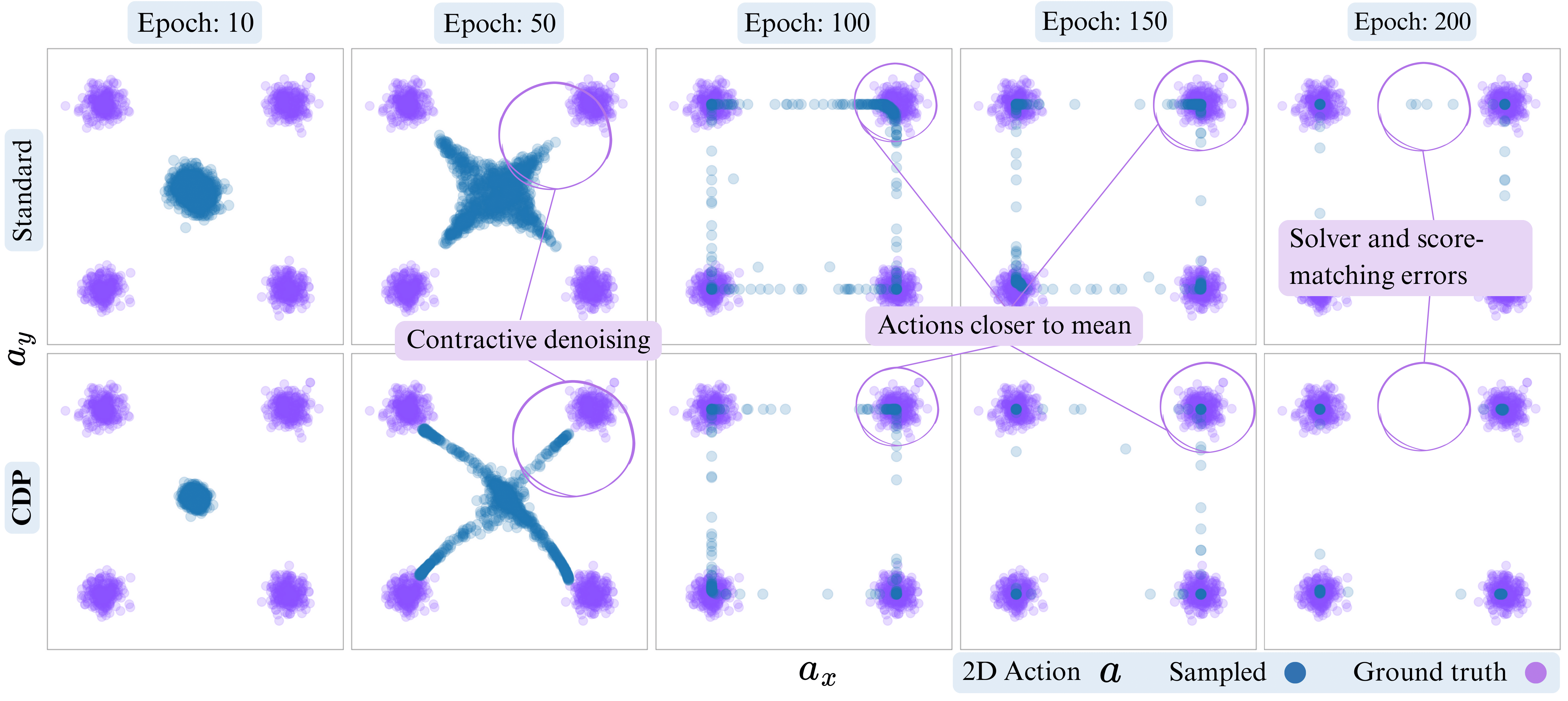
To take a closer look, we compare CDP against vanilla diffusion during training by sampling from the learned policy at each epoch. This illustrates how contraction reshapes the sampling process, concentrating actions near meaningful modes for improved accuracy.
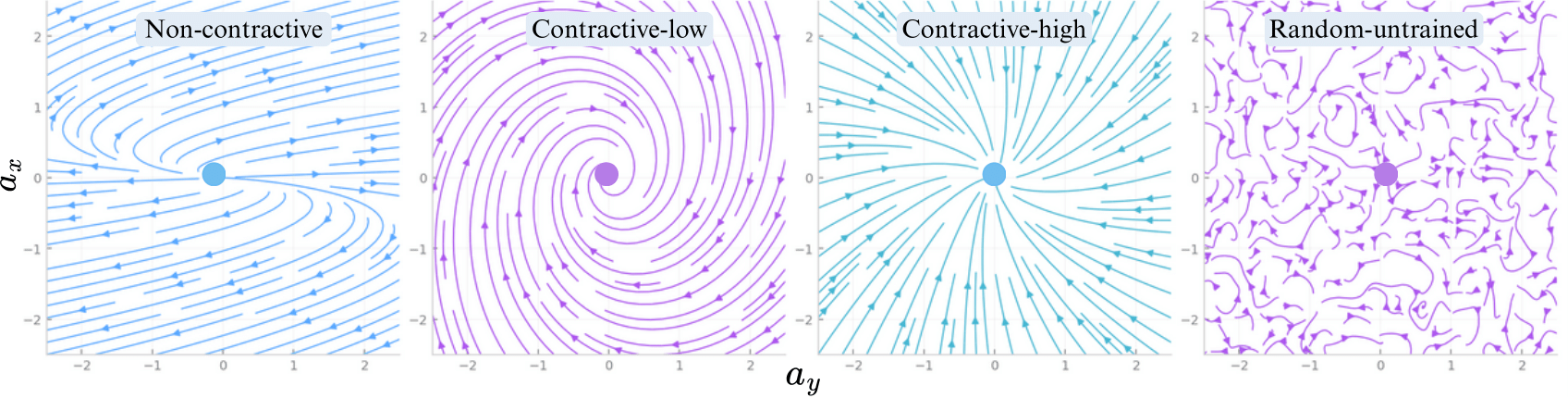
Prior work shows contraction in diffusion sampling reduces score-matching and discretization errors; CDP adapts this with promoting contraction along reverse ODE trajectories.
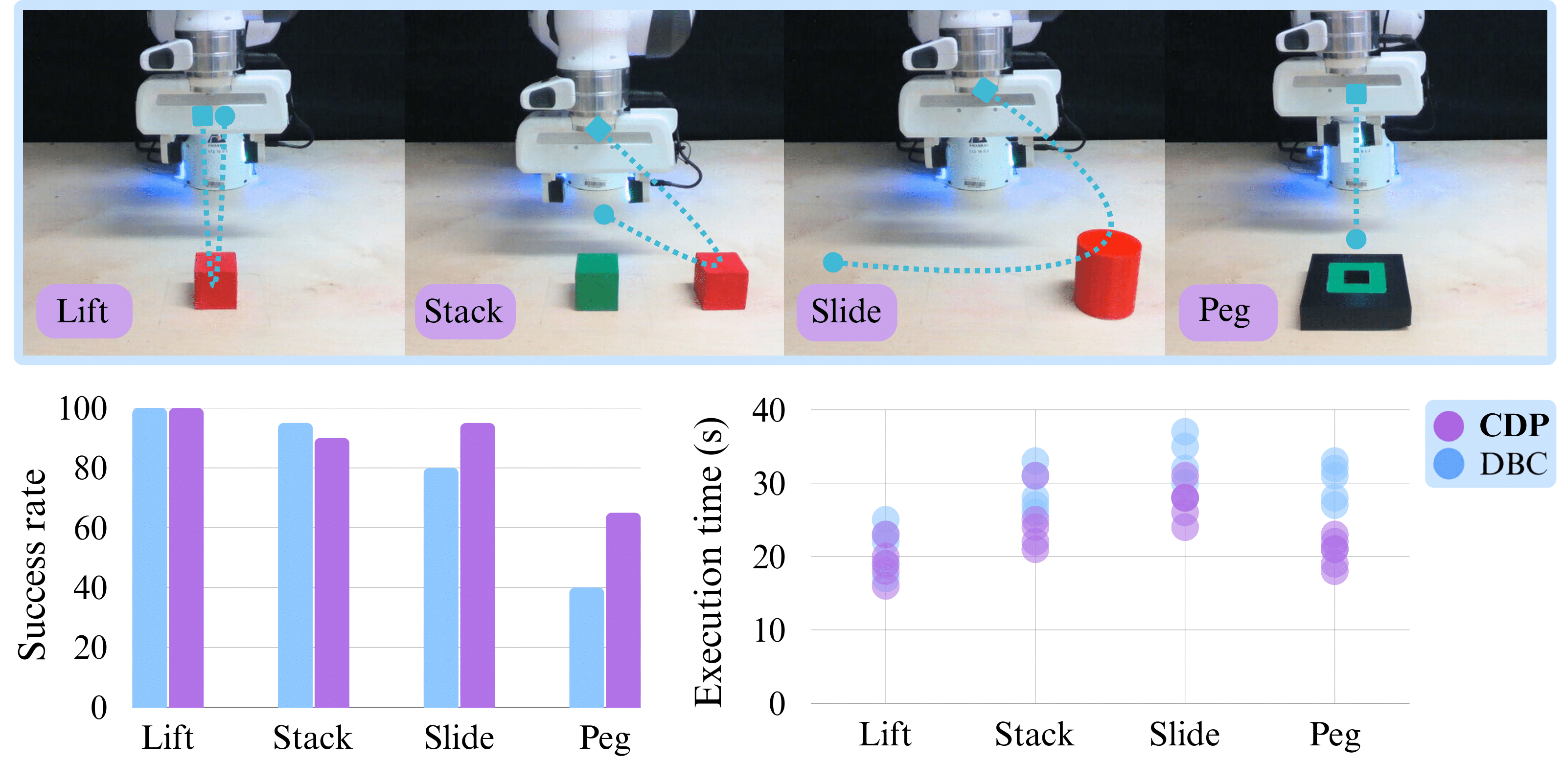
CDP is benchmarked extensively on D4RL and Robomimic benchmarks in simulation, but we also deploy CDP on a real Franka robot arm to showcase its reliability in the real world. To make learning more challenging, we do not use a wrist view, only agent view observations are available to the model. This makes consistency of action generation even more critical, especially in Slide and Peg tasks.
@inproceedings{
abyaneh2026contractive,
title={Contractive Diffusion Policies: Robust Action Diffusion via Contractive Score-Based Sampling with Differential Equations},
author={Amin Abyaneh and Charlotte Morissette and Mohamad H. Danesh and Anas Houssaini and David Meger and Gregory Dudek and Hsiu-Chin Lin},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=iKJbmx1iuQ}
}